Function to compute the proportions of a set of several binary variables or means or medians of a set of quantitative variables, based on complex survey data.
It produces a list containing a table, including the confidence intervals of the indicators and a ready-to-be published ggplot graphic. The confidence intervals are taking into account the complex survey design.
Exporting the results to an Excell file is possible.
Usage
many_val(
data,
list_vars,
type,
list_vars_lab = NULL,
facet = NULL,
filter_exp = NULL,
...,
na.rm.facet = TRUE,
na.vars = "rm",
prop_method = "beta",
reorder = FALSE,
show_ci = TRUE,
show_n = FALSE,
show_value = TRUE,
show_labs = TRUE,
scale = NULL,
digits = 0,
unit = NULL,
dec = NULL,
col = NULL,
pal = "OBSS_alt3",
direction = 1,
desaturate = 0,
lighten = 0,
darken = 0,
dodge = 0.9,
font = "Roboto",
wrap_width_y = 25,
title = NULL,
subtitle = NULL,
xlab = NULL,
ylab = NULL,
caption = NULL,
lang = "fr",
theme = "fonctionr",
coef_font = 1,
export_path = NULL
)
many_prop(..., type = "prop")
many_median(..., type = "median")
many_mean(..., type = "mean")Arguments
- data
A dataframe or an object from the survey package or an object from the srvyr package.
- list_vars
A vector containing the names of the dummy/quantitative variables on which to compute the proportions/means/medians.
- type
"prop"to compute proportions ;"mean"to compute means ;"median"to compute medians.- list_vars_lab
A vector containing the labels of the dummy/quantitative variables to be displayed on the graphic and in the table of result. Default uses the variable names in
list_vars.- facet
A variable defining the faceting group.
- filter_exp
An expression filtering the data, preserving the design. Notice that
filter_expworks assrvyr::filter(): it excludes observations for whichfilter_expresults intoNA. It is often the case whenNAis present on one of the filter variables.- ...
All options possible in
srvyr::as_survey_design().- na.rm.facet
TRUEif you want to remove observations withNAon the facet variable.FALSEif you want to create a facet with theNAvalues for the facet variable. Default isTRUE.- na.vars
The treatment of
NAvalues in variables (list_vars)."rm"removesNAseperately in each individual variable,"rm.all"removes every individual that has at least oneNAin one variable. Default is"rm".- prop_method
Type of proportion method used to compute confidence intervals. See
survey::svyciprop()for details. Default is beta method. This argument is only used in case oftype = "prop".- reorder
TRUEif you want to reorder the variables according to the proportions/means/medians. Default isFALSE.- show_ci
TRUEif you want to show the error bars on the graphic.FALSEif you don't want to show the error bars. Default isTRUE.- show_n
TRUEif you want to show on the graphic the number of observations in the sample for each variable. The number can varie ifna.vars = "rm".FALSEif you do not want to show this number. Default isFALSE.- show_value
TRUEif you want to show the proportions/means/median for each variable on the graphic.FALSEif you do not want to show the proportions/means/medians. Default isTRUE.- show_labs
TRUEif you want to show axes labels.FALSEif you do not want to show any labels on axes. Default isTRUE.- scale
Denominator of the proportions. Default is
100to interpret numbers as percentages. This argument is only used in case oftype = "prop".- digits
Number of decimal places displayed on the values labels on the graphic. Default is
0.- unit
Unit displayed on the graphic. Default is percent for
type = "prop"and no unit fortype = "mean"or"median".- dec
Decimal mark displayed on the graphic. Default depends on lang:
","for fr and nl ;"."for en.- col
Color of the bars if the user wants a monocolor graph.
colmust be a R color or an hexadecimal color code. Aspalhas a priority overcol, if the user wants to usecol, he must not use simultaneously thepalargument (evenpal = NULL).- pal
Colors of the bars if the user wants the bars to have different colors.
palmust be vector of R colors or hexadecimal colors or a palette from packages MetBrewer or PrettyCols or a palette from fonctionr.palhas a priority overcol.- direction
Direction of the palette color. Default is
1. The opposite direction is-1.- desaturate
Numeric specifying the amount of desaturation where
1corresponds to complete desaturation (no colors, grey layers only),0to no desaturation, and values in between to partial desaturation. Default is0. It affects only the palette (pal) and not the monocolor (col). Seecolorspace::desaturate()for details. If desaturate and lighten/darken arguments are used, lighten/darken is applied in a second time (i.e. on the color transformed by desaturate).- lighten
Numeric specifying the amount of lightening. Negative numbers cause darkening. Value shoud be ranged between
-1(black) and1(white). Default is0. It affects only the palette (pal) and not the monocolor (col). Seecolorspace::lighten()for details. If both argument ligthen and darken are used (not advised), darken is applied in a second time (i.e. on the color transformed by lighten).- darken
Numeric specifying the amount of lightening. Negative numbers cause lightening. Value shoud be ranged between
-1(white) and1(black). Default is0. It affects only the palette (pal) and not the monocolor (col). Seecolorspace::darken()for details. If both argument ligthen and darken are used (not advised), darken is applied in a second time (i.e. on the color transformed by lighten).- dodge
Width of the bars. Default is
0.9to let a small space between bars. A value of1leads to no space betweens bars. Values higher than1are not advised because they cause an overlaping of the bars.- font
Font used in the graphic. See
load_and_active_fonts()for available fonts. Default is"Roboto".- wrap_width_y
Number of characters before going to the line for the labels of the groups. Default is
25.- title
Title of the graphic.
- subtitle
Subtitle of the graphic.
- xlab
X label on the graphic. As
ggplot2::coord_flip()is used in the graphic,xlabrefers to the x label on the graphic, after theggplot2::coord_flip(), and not to the x variable in the data. Default (xlab = NULL) displays, fortype = prop, "Proportion :" (iflang = "fr"), "Proportion:" (iflang = "en") or "Aandeel:" (iflang = "nl"), or, fortype = "mean", "Moyenne :" (iflang = "fr"), "Mean:" (iflang = "en") or "Gemiddelde:" (iflang = "nl"), or, fortype = "median", "Médiane :" (iflang = "fr"), "Median:" (iflang = "en") or "Mediaan:" (iflang = "nl"), followed by the labels of the variables (list_vars_lab). To show no X label, usexlab = "".- ylab
Y label on the graphic. As
ggplot2::coord_flip()is used in the graphic,ylabrefers to the y label on the graphic, after theggplot2::coord_flip(), and not to the y variable in the data. Default (ylab = NULL) displays no Y label.- caption
Caption of the graphic.
- lang
Language of the indications on the graphic. Possibilities are
"fr"(french),"nl"(dutch) and"en"(english). Default is"fr".- theme
Theme of the graphic. Default is
"fonctionr"."IWEPS"adds y axis lines and ticks.NULLuses the default grey ggplot2 theme.- coef_font
A multiplier factor for font size of all fonts on the graphic. Default is
1. Usefull when exporting the graphic for a publication (e.g. in a Quarto document).- export_path
Path to export the results in an xlsx file. The file includes two sheets: the table and the graphic.
Examples
# Loading of data
data(eusilc, package = "laeken")
# Recoding variables
eusilc$worker <- 0
eusilc$worker[eusilc$pl030 == "1"]<-1
eusilc$worker[eusilc$pl030 == "2"]<-1
eusilc$austrian<-0
eusilc$austrian[eusilc$pb220a == "AT"]<-1
# Computation, taking sample design into account
eusilc_many_prop <- many_prop(
eusilc,
list_vars = c(worker,austrian),
list_vars_lab = c("% of workers","% of Austrian"),
facet = rb090,
strata = db040,
ids = db030,
weight = rb050,
title = "Proportion of workers and Autrian according to gender",
subtitle = "Example with austrian SILC data from 'laeken' package"
)
#> Variables used: worker, austrian
#> Input: data.frame
#> Sampling design -> ids: db030, strata: db040, weights: rb050
#> Numbers of observation(s) removed by each filter (one after the other):
#> 0 observation(s) removed due to missing facet
#> Warning: With na.vars = 'rm', observations removed differ between variables
# Results in graph form
eusilc_many_prop$graph
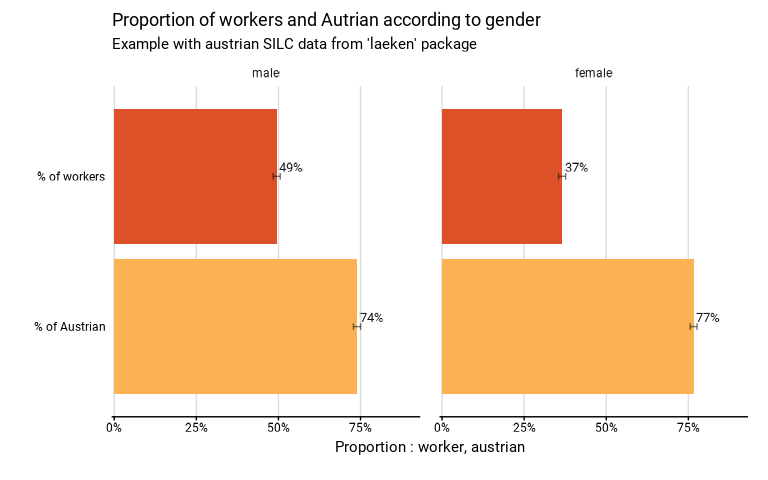 # Results in table format
eusilc_many_prop$tab
#> # A tibble: 4 × 12
#> rb090 list_col prop prop_low prop_upp n_sample n_true_weighted
#> <fct> <fct> <dbl> <dbl> <dbl> <int> <dbl>
#> 1 male % of workers 0.495 0.484 0.506 7267 1969092.
#> 2 female % of workers 0.366 0.355 0.376 7560 1536897.
#> 3 male % of Austrian 0.739 0.728 0.750 7267 2942211.
#> 4 female % of Austrian 0.766 0.756 0.777 7560 3219916.
#> # ℹ 5 more variables: n_true_weighted_low <dbl>, n_true_weighted_upp <dbl>,
#> # n_tot_weighted <dbl>, n_tot_weighted_low <dbl>, n_tot_weighted_upp <dbl>
# Results in table format
eusilc_many_prop$tab
#> # A tibble: 4 × 12
#> rb090 list_col prop prop_low prop_upp n_sample n_true_weighted
#> <fct> <fct> <dbl> <dbl> <dbl> <int> <dbl>
#> 1 male % of workers 0.495 0.484 0.506 7267 1969092.
#> 2 female % of workers 0.366 0.355 0.376 7560 1536897.
#> 3 male % of Austrian 0.739 0.728 0.750 7267 2942211.
#> 4 female % of Austrian 0.766 0.756 0.777 7560 3219916.
#> # ℹ 5 more variables: n_true_weighted_low <dbl>, n_true_weighted_upp <dbl>,
#> # n_tot_weighted <dbl>, n_tot_weighted_low <dbl>, n_tot_weighted_upp <dbl>